




When an exploit starts at 02:17, what happens in the next ten minutes?
If an exploit starts at 02:17, the only question that matters is straightforward. Who sees it first, who has authority to act, and what happens in the next ten minutes.
Many organizations can describe their security reviews and monitoring. Fewer can describe their response path with the same precision. That gap is where incidents turn into losses, especially when systems span multiple chains, custody layers, and governance processes, and when the initial access path looks like a Web2 problem, phishing, account takeover, or compromised endpoints.
In our Hypernative x Cantina webinar, Cantina President Mike Leffer and Hypernative VP of Strategy Marshall Lipman laid out why Managed Detection and Response is becoming the default operating model for 2026, and what institutions increasingly expect organizations to prove: rehearsed playbooks, defined authority, auditable actions, and a dependable route from detection to containment under off hours conditions.
Why now
Three shifts are converging.
Protocols now operate across more surfaces than the contract layer. The incident path runs through onchain execution, offchain infrastructure, privileged access, third party services, and governance. A failure in one layer can cascade into losses in another.
Institutional engagement is rising, but the standard is changing. Banks and asset managers can accept technical novelty. They do not accept vague operations. Diligence increasingly focuses on ownership, escalation paths, evidence trails, and how fast an organization can contain a credible threat.
Attack patterns are converging. The trigger is often Web2 shaped, phishing, session compromise, endpoint malware, vendor access, then it becomes Web3 shaped within minutes, compromised approvals, signer actions, parameter changes, treasury movement, liquidity drains.
MDR becomes relevant because it binds these realities into one workflow. It is the difference between having signals and being able to act on them consistently.
Common response failures in Web3
The panel returned to the same failure modes that show up across incidents, regardless of chain or protocol design.
No clear triage ownership: alerts land in shared channels, everyone sees them, no one owns the first decision. The clock runs while the organization aligns.
Fragmented tooling: monitoring, chat, incident tracking, and governance controls sit in different systems. Operators spend time stitching context together instead of containing.
Disconnected detection and response: a signal is validated, but the next step is unclear. Which playbook applies, who approves, who presses pause, who notifies partners, who documents the evidence.
Operational delays that create institutional fallout. The damage is not only financial. Slow containment creates uncertainty, uncertainty becomes reputational harm, and institutions treat that as a control failure.
A simple way to summarize the point from the discussion is that readiness is measured in decisions, not in dashboards.
MDR in action, from detection to containment
The practical picture the panel outlined is a combined model.
Hypernative covers real time detection across onchain behavior, policy based alerting, and integrations that can surface credible risks early enough to matter. Cantina MDR covers the operating model that turns those signals into consistent containment, including roles, approvals, rehearsals, and traceable execution.
When the workflow works, it looks like a sequence that is predictable under pressure.
First, the organization knows what it is protecting. Crown jewels, critical contracts, critical keys, dependencies, and the blast radius those dependencies create.
Second, the organization has a response structure that matches its governance. Clear escalation paths, clear authority for emergency actions, and playbooks that map specific signals to specific steps, including what gets verified by humans and what can be executed reliably.
Third, the organization rehearses. Tabletop exercises and attack simulations pressure test both the playbooks and the social reality of response. Who is reachable, which signers respond, where approvals stall, where communications break, and which actions should be automated.
Fourth, the organization maintains a single incident surface. Alerts become incidents with context attached, incident actions are executed and logged, and collaboration tools become part of the workflow rather than a parallel narrative.
This is where the MDR layer model matters as a shared language for how you operate:
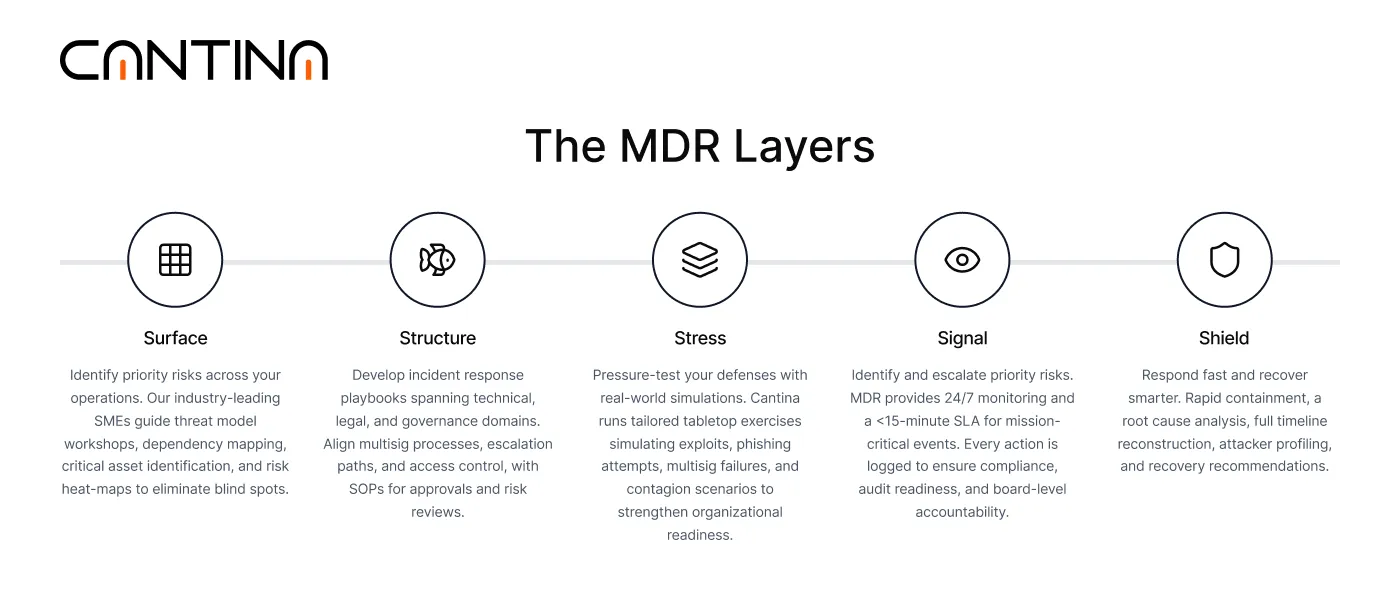
What institutions are demanding now
A recurring theme in the webinar was that diligence is becoming operational.
Institutions want to know whether an organization can explain its controls and demonstrate that those controls work when people are offline. This shows up in diligence questionnaires, legal reviews, and partner conversations as a consistent set of expectations.
Clear responsibilities. Who owns triage, who owns containment actions, who owns communications, and how handoffs work.
Documented playbooks. Not a generic incident plan, but playbooks tied to likely scenarios and to the organization’s actual control surface.
Evidence trails. Logging, decision history, and timelines that can survive post incident review. Institutions need confidence that the organization can explain what happened.
Rehearsal and readiness. Practice runs that demonstrate the organization has tested its escalation paths and emergency controls before a real incident.
For 2026, the standard moves toward proof. Institutions will increasingly treat MDR as a prerequisite, not as an enhancement.
Implementing MDR without internal burden
The closing segment of the webinar focused on practicality. MDR has to reduce load, not add complexity.
Implementation is structured, and it is measurable.
Start with a risk map, then define playbooks and approvals, then rehearse through simulations, then turn repeatable steps into controlled automation. Keep human verification where judgment is required, remove decision latency where it is avoidable, and ensure every action is logged.
This is also where collaboration between detection and response becomes additive. Hypernative can surface credible signals early. Cantina MDR ensures those signals have an owned path to containment, even when it is late, even when it is messy, and even when governance is slow.
The standard for 2026
A useful test for readiness is blunt.
If a credible incident started tonight, who sees it first, who has authority to act, and what happens in the next ten minutes.
If the answer is vague, the organization is relying on hope, not controls.
The purpose of MDR is to replace hope with a practiced system.
Closing
If you want to pressure test your current response readiness posture, Cantina and Hypernative run a joint security program that maps your exposure, tunes detection to what matters, and makes the detection to containment route explicit.
Contact us to get started, book a demo today.