




Key Takeaways
- Design maturity in DeFIAI systems is trailing capital inflow. While deposits into AI-integrated protocols are increasing, many lack defined coordination logic, fallback behavior, or role separation, which limits their readiness for institutional review.
- Many AI-integrated protocols currently operate without widely adopted or on-chain validation paths, particularly around inference outputs. Outputs are often treated as deterministic, with a limited ability to trace decisions, challenge errors, or replay model behavior, which raises risk when capital or governance is at stake.
- Institutional readiness hinges on coordination clarity. Protocols that can surface role definitions, dispute handling, and security reviewability of AI-driven actions will be better positioned for integrations, assessments, and long-term confidence.
Introduction
Protocol teams are beginning to integrate AI into on-chain coordination, encompassing execution logic, inference systems, and agent-based automation. Capital is already flowing into re-staking layers, inference-driven protocols, and delegated task networks. While interest is growing, many designs are still defining how coordination works in practice: how outputs are verified, how roles interact, and what happens when something fails. This article examines the design patterns emerging in DeFIAI systems, the coordination gaps that still exist, and how Cantina helps teams make those systems legible without slowing down development.
TVL Is Increasing, but Visibility Into Behavior Still Varies
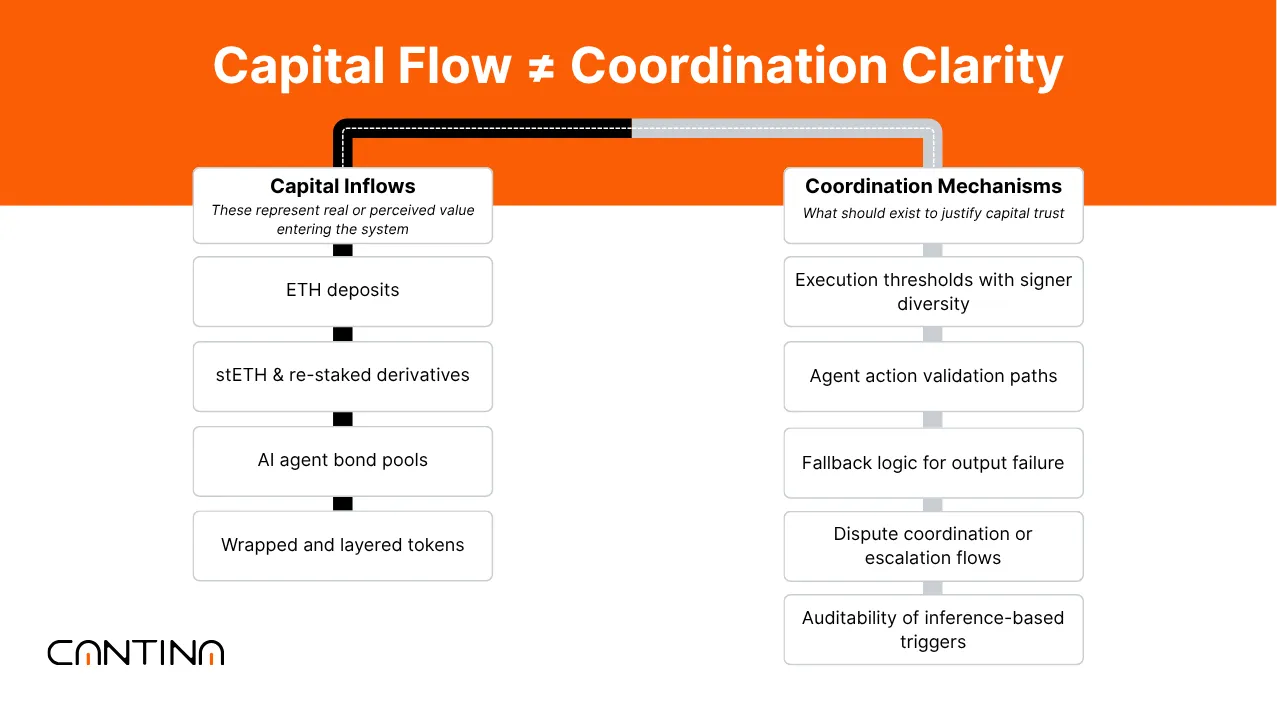
Capital Is Moving, but Coordination Isn’t Always Clear
We’re seeing more deposits flow into AI-integrated protocols, especially those working on inference, restaking, or delegated execution. That momentum is real. However, upon closer examination, it becomes clear that design maturity isn’t always keeping pace with capital inflow.
As in many early-stage protocols, TVL in DeFIAI systems may reflect recursive deposits or wrapped assets across layers, which can obscure actual exposure. That’s expected early on, but it complicates attempts to gauge actual exposure.
What matters more is how that capital’s being used, whether it’s backing operator performance, validating inference outputs, or anchoring dispute resolution. Without clear links between value and behavior, it becomes harder to assess how the system performs under stress.
Coordination Links Are Still Taking Shape
When a protocol ties capital to clearly defined roles, i.e., who proposes, who executes, and who can challenge, it becomes easier to reason about system behavior. But in many DeFIAI designs, those lines are still blurred. We’ve reviewed systems where model outputs trigger actions directly, without a clear fallback in place in case of failure, or without a means to verify the result.
In those cases, it’s not just about whether the AI is right, it’s about whether there’s any structure around what happens when it isn’t. If behavior can’t be traced or challenged, risk compounds fast, especially as TVL grows.
TVL will continue to be a signal for interest, but it’s not enough on its own. What matters to institutional reviewers is whether capital flows are tied to observable coordination logic. That’s what creates confidence, and that’s where deeper review adds value.
Use Cases Are Being Deployed, Even as Observability Remains Limited
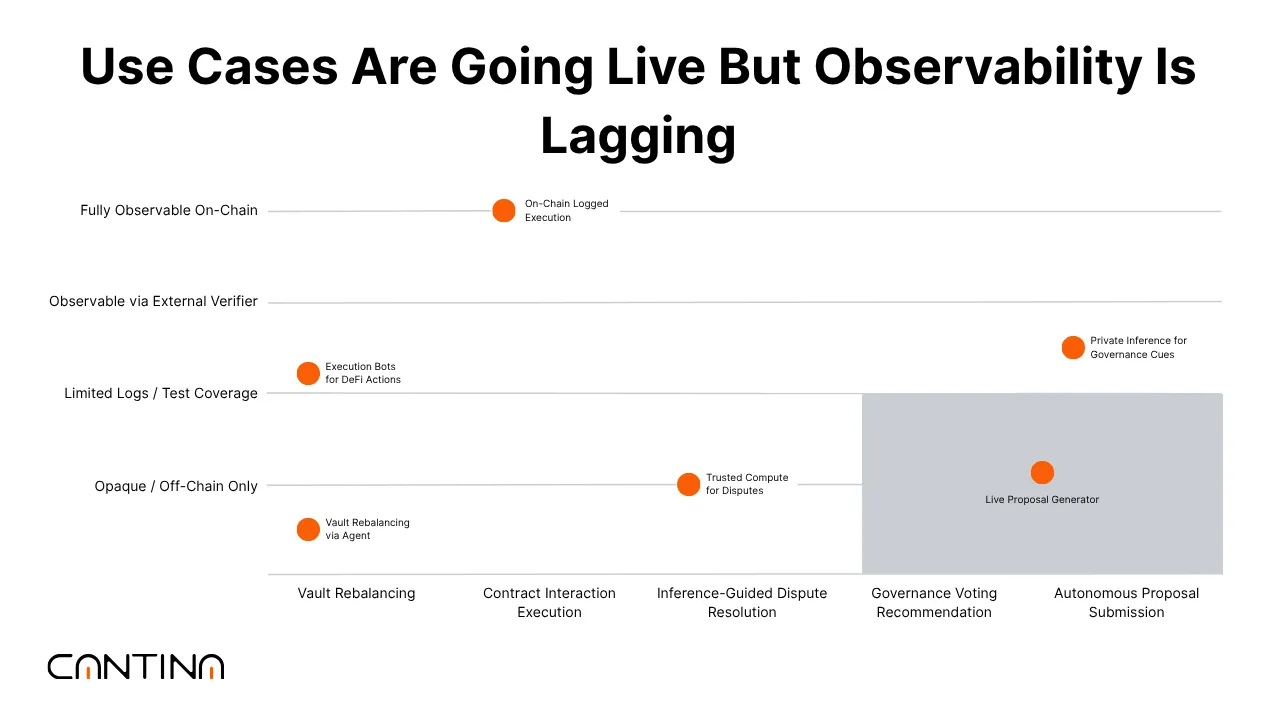
AI Functions Are Getting Wired Into Execution
Teams are starting to connect AI agents directly to protocol logic, which handles vault rebalancing, submits contract interactions, or feeds signals into governance. In some cases, these outputs originate from models running within trusted execution environments, particularly when privacy or proprietary model design is involved.
What’s often missing is a way to see how those outputs came to be. On-chain, you might get the result, but there is no transparency into what prompt was used, what version of the model was run, or what data was fed in. That gap makes it hard for other participants, reviewers, governance roles, and even other agents to trust or verify what they’re acting on.
Patterns Around Control Are Still Forming
Across the systems we've reviewed, roles such as proposer, validator, and executor tend to blur together. In some cases, a single agent performs all three. That setup might work under normal conditions, but it introduces fragility. If something goes wrong, such as bad input, unexpected output, or simply silence, it’s often unclear how the protocol handles it.
Fallback logic may appear in documentation, but it’s rarely implemented directly in contracts, especially for inference-triggered execution paths. There’s usually no threshold logic for rejecting an inference, no escalation if a model stalls, and no timeout behavior coded in. Protocols are trusting the model to respond and the system to accept that response. However, without guardrails, those assumptions become liabilities as usage scales up.
Security Reviewability and Replay Are Rarely Built In
Inference tends to get treated as a point-in-time function: the model answered, and now it’s acted on. But models shift. Prompts evolve. Data inputs aren’t always consistent. Without structured logs or signed attestations, it’s rarely possible to replay the same call and confirm the outcome.
Few DeFIAI systems implement mechanisms like slashing, quorum fallback, or continuous health checks often because the architectural patterns for agent accountability are still maturing.
That creates problems during incident review or governance disputes. It also slows down institutional evaluations, where repeatability and traceability are baseline expectations, not advanced features.
Readiness Comes Down to How Roles and Behavior Are Structured
For protocols moving toward greater automation, what's being asked isn’t whether the model works; it’s whether the system can demonstrate how it worked, who was involved, and what happens if something goes awry. That’s where most designs are still catching up.
Versioned inputs, logged outputs, and fallback plans don’t need to be complex. But they do need to exist. As these systems assume more responsibility for moving funds, shaping governance, and coordinating execution, reviewers are increasingly seeking clarity in the coordination layer. It’s not about locking things down. It’s about making them legible enough to trust.
Model Outputs Are Being Used Without Consistent Verification Paths
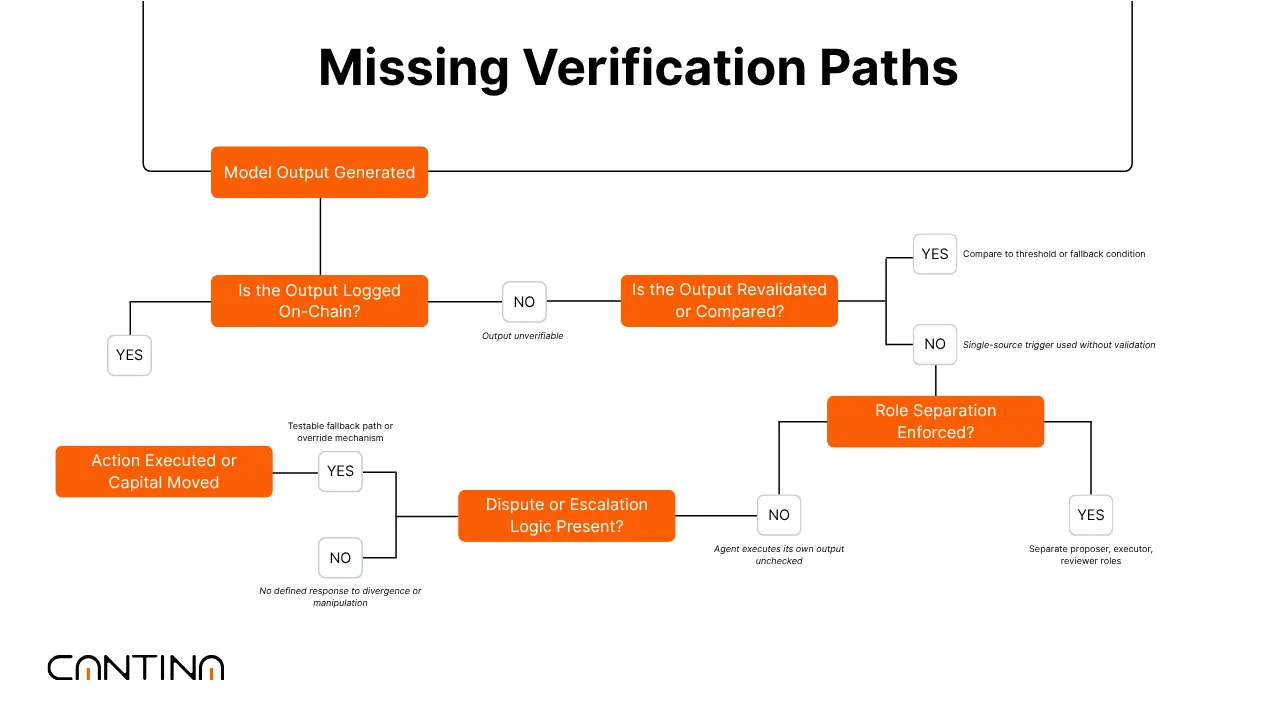
Probabilistic Outputs Are Being Treated as Deterministic Triggers
Model outputs are being used in live systems to inform decisions, such as selecting actions, allocating funds, or advancing protocol state. These outputs are shaped by context: the model version, the prompt, recent data, and even subtle input changes. Yet in many protocols, they’re handled as if they’re definitive.
Across several deployments, we’ve seen model-generated decisions transition directly into execution without a second layer of review or a mechanism for verifying consistency. There is often no clear path to compare outputs across agents or timeframes, and no structure for saying, “This looks off, pause before acting.”
Gaps in Role Clarity and Error Handling Are Common
A recurring pattern is the lack of role separation between those who generate, review, and act on a model output. In many designs, the same agent proposes an action and triggers its execution, with no independent checkpoint or oversight layer in between. That setup creates exposure, especially when inference outcomes vary under identical or near-identical inputs.
Protocols also tend to skip over dispute handling for inference discrepancies. There’s usually no defined response for divergent outputs, no on-chain logging of model behavior, and no mechanism to escalate or roll back actions based on unexpected outcomes. These gaps may remain hidden during routine operation but become critical under stress, particularly during security reviews, incident reviews, or governance disputes.
Agents Are Taking On Validator-Like Roles Without Shared Safeguards
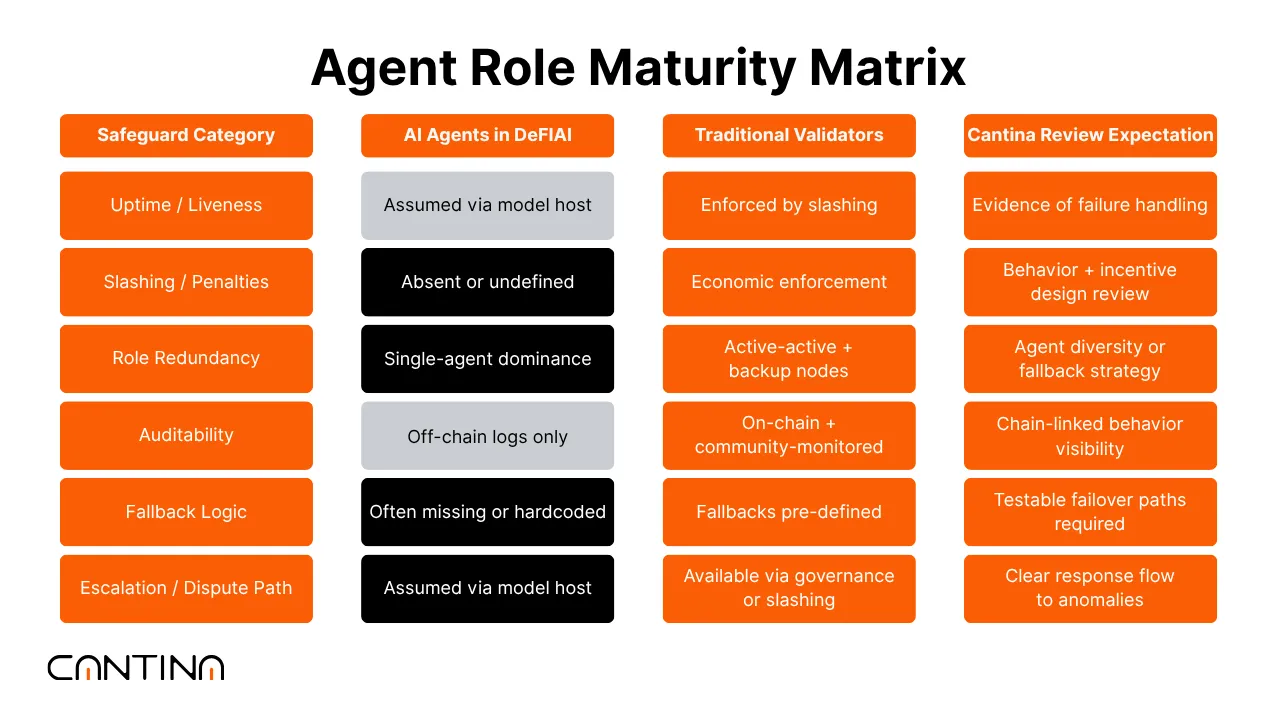
Validator-Level Responsibilities Without Validator-Level Protections
In many of the newer AI-integrated systems, agents are beginning to assume operational responsibilities that resemble validator roles. They’re submitting signed messages, triggering state changes, and coordinating execution across contracts. But while the responsibilities are growing, the protections around them often aren’t.
Unlike validator networks, these agent systems rarely define expectations around uptime, fault handling, or misbehavior. Few DeFI AI systems implement mechanisms like slashing, quorum fallback, or continuous health checks, which are commonly found in validator networks.
In several cases, the protocol relies on a single model service, without redundancy or delegation, and assumes the agent will behave consistently over time.
Design Often Skips Over Known Risk Patterns
Where traditional validators are subject to strict role definitions and system constraints, AI agents often operate without the same guardrails. Known risks, such as prompt injection, input manipulation, or biased interpretation, are typically not directly addressed in protocol logic. There’s also limited testing or simulation of how agents behave under edge conditions or conflicting inputs.
Without role diversity or challenge mechanisms, systems are vulnerable to subtle yet compounding risks, particularly as agent logic begins to drive higher-value decisions. These are solvable issues, but they require teams to treat agents not just as helpers, but as infrastructure-level participants. That framing is still catching up to the design pace.
How Cantina Can Contribute to DeFIAI Protocol Reviews
AI-driven coordination layers are taking shape, and Cantina can support protocol teams working at the intersection of inference, automation, and smart contract enforcement. We focus on surfacing coordination risks, validating role structure, and making operational behavior legible to both internal teams and external reviewers.
For teams building or scaling DeFIAI systems, we can support review efforts in areas like:
- Agent accountability – Can outputs be validated, questioned, or disputed in a structured way?
- Role clarity and delegation – Are proposer, executor, and reviewer roles clearly defined and separable?
- Fallback and recovery logic – What happens when outputs are missing, inconsistent, or outside expected bounds?
- Dispute handling – Are there testable mechanisms for challenging, overriding, or escalating disputes?
- Governance dependencies – How tightly is protocol state or capital flow tied to model or agent behavior?
These reviews are designed to help teams pressure-test assumptions and strengthen coordination logic, without slowing design momentum. As inference layers begin to play validator-like roles, structured validation becomes a baseline for long-term confidence.
Conclusion
AI-linked protocols are pushing new boundaries in automation, governance, and execution. However, as agent logic assumes more responsibility, questions surrounding verification, accountability, and fallback handling become increasingly critical. Cantina helps teams bring clarity to this layer, making coordination structures legible and aligning them with what institutional reviewers need to see. If you're building or evaluating these systems, we’re here to support with structured, security-led reviews. Let’s connect.
FAQs
What is DeFIAI, and how does it differ from traditional DeFi?
DeFIAI refers to protocols that integrate AI agents or inference systems into core DeFi operations, such as execution logic, coordination, and governance. Unlike traditional DeFi, where roles and behavior are typically deterministic and code-defined, DeFIAI introduces probabilistic model behavior, making coordination, verification, and fallback logic more complex and less standardized.
Why is coordination logic important in AI-integrated protocols?
Coordination logic defines how roles interact, who proposes, who executes, and who can challenge the proposal. In AI-integrated systems, this structure becomes critical because agent outputs often trigger high-impact decisions without traditional checkpoints. Without clear coordination paths, fallback behavior, and auditability, the protocol’s operational risk increases, especially under institutional scrutiny.
What are the key risks in using AI agents for on-chain execution?
Key risks include treating model outputs as deterministic, a lack of version control or input logging, role overlap (e.g., proposer and executor being the same agent), and missing fallback or dispute mechanisms. These gaps can lead to silent failures, untraceable actions, and fragility under stress, making protocols less resilient and harder to review.
How can DeFIAI protocols improve their institutional readiness?
Protocols can enhance readiness by implementing role separation, logging inference inputs and outputs, designing fallback and timeout logic, and enabling dispute resolution mechanisms. These structures help make AI behavior legible, repeatable, and auditable core expectations for integrations, security assessments, and governance evaluations.
What does Cantina offer for teams building DeFIAI systems?
Cantina helps DeFIAI teams surface and resolve coordination risks through structured, security-led reviews. This includes evaluating agent accountability, validating role definitions, testing fallback paths, and assessing governance dependencies. By making these systems legible to institutional reviewers, Cantina supports the scaling of safer protocols without slowing down innovation.